上周刚拿到 MacBook Air(16G+512G)时,就计划装一个本地 AI 模型。根据配置建议,理论上可以运行 8B 级别的本地模型。我尝试通过 Ollama 安装 qwen3:8b 和 qwen3:4b,但都报错:
ollama pull qwen3:8b
pulling manifest
pulling a3de86cd1c13: 100% ▕█████████████████████████████████████████████████████████████████████▏ 5.2 GB
pulling 05a61d37b084: 100% ▕█████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
huilang@MacBook-Air ~ % ollama run qwen3:8b
Error: 500 Internal Server Error: model failed to load, this may be due to resource limitations or an internal error, check ollama server logs for details换了 4B 版本同样失败,只好放弃。
前几天看到 Google TurboQuant 技术可以大幅降低内存占用:
TurboQuant是 Google 在大模型推理方向提出的一类高性能量化(Quantization)技术方案,核心目标是:
在尽量不损失模型精度的前提下,大幅降低显存占用 + 推理延迟。
新型在线向量量化算法,实现零精度损失的 3-bit KV Cache 压缩,内存减少 6 倍,速度提升 8 倍。
早上发现 Atomic Chat 工具已自动集成 TurboQuant + UI,立即安装测试。选择 Qwen3.5-9B 后,下载完成即进入对话界面:

安装就是常规的双击拖拽到应用程序文件夹,打开后选择模型下载即可,我选了Qwen3.5-9B。下载完就是对话界面了,简单测试下,结果如下图
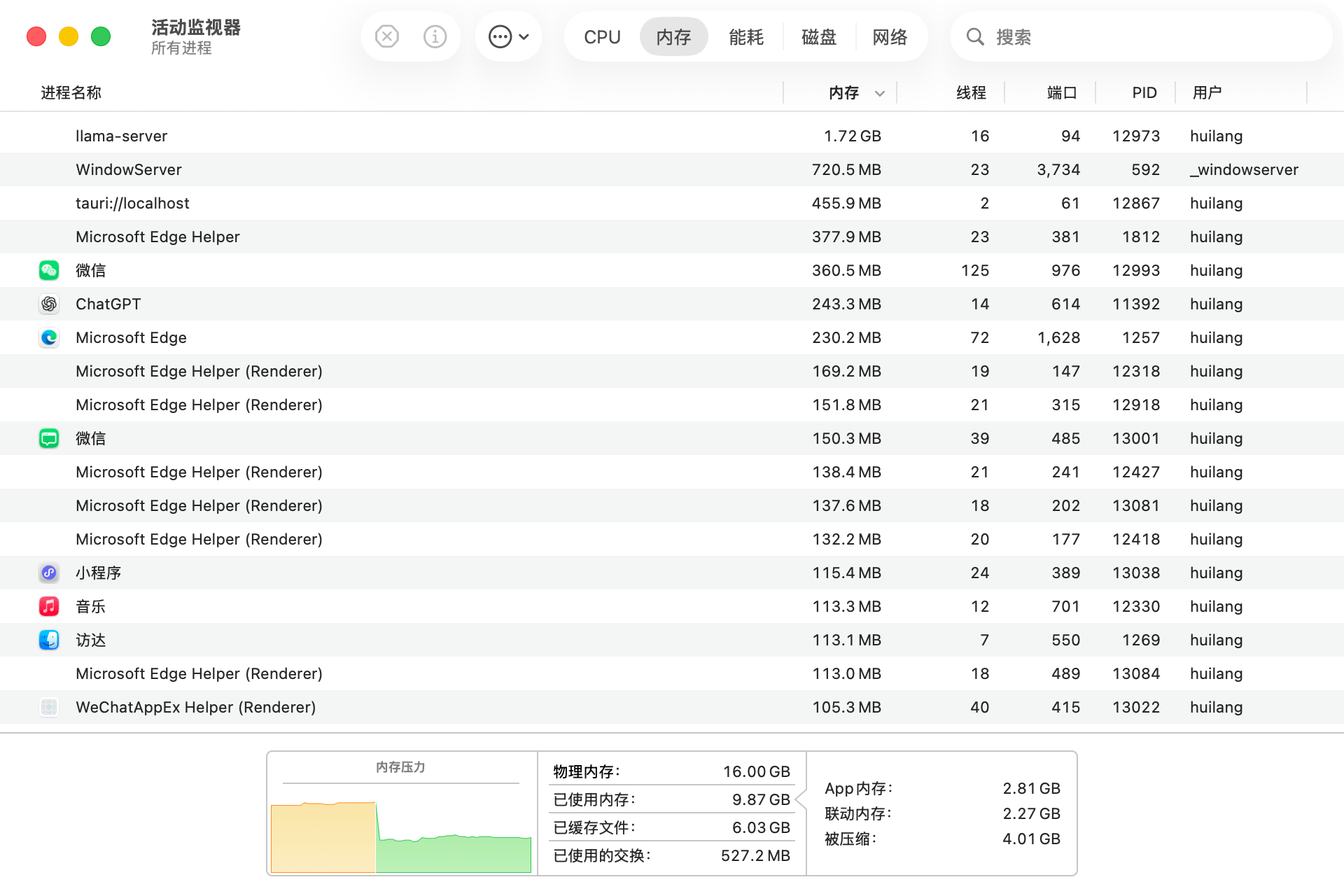
这是内存占用图,内存压力左侧黄色是在模型输出的时候的占用,绿色是停止输出后的占用。电脑稍微有点发热,停止输出后就降温了。
测试结果:
- 输出速度:18 tokens/sec(表现不错)
- 内存占用:模型运行时压力稍高,停止输出后迅速降温
- CUP占用:闲置CPU在81-95%波动,完全没压力
- 联网搜索:支持实时搜索功能
换成Qwen3.5-4B的时候,内存完全没压力,内存压力表还是绿色的,笔记本温度基本没什么变化,输出速度28tokens/sec,至于CPU,几乎没怎么占用,空闲92-95%多左右。
后续会继续观察实际应用场景中的整体表现。
后续换上了LM Studio + Apple优化的MLX模型,实测Qwen3.5-9b 26tokens/s,Qwen3.5-4b 41tokens/s,效率提升明显,怀疑Atomic Chat根本没用上Google TurboQuant。
昨天ollama0.19预览版(2026-03-30)也支持MLX模型了,说是大幅度提升,但目前只支持Qwen3.5-35b,需要最低32G统一内存,继续观望。
